Support Vector Machine
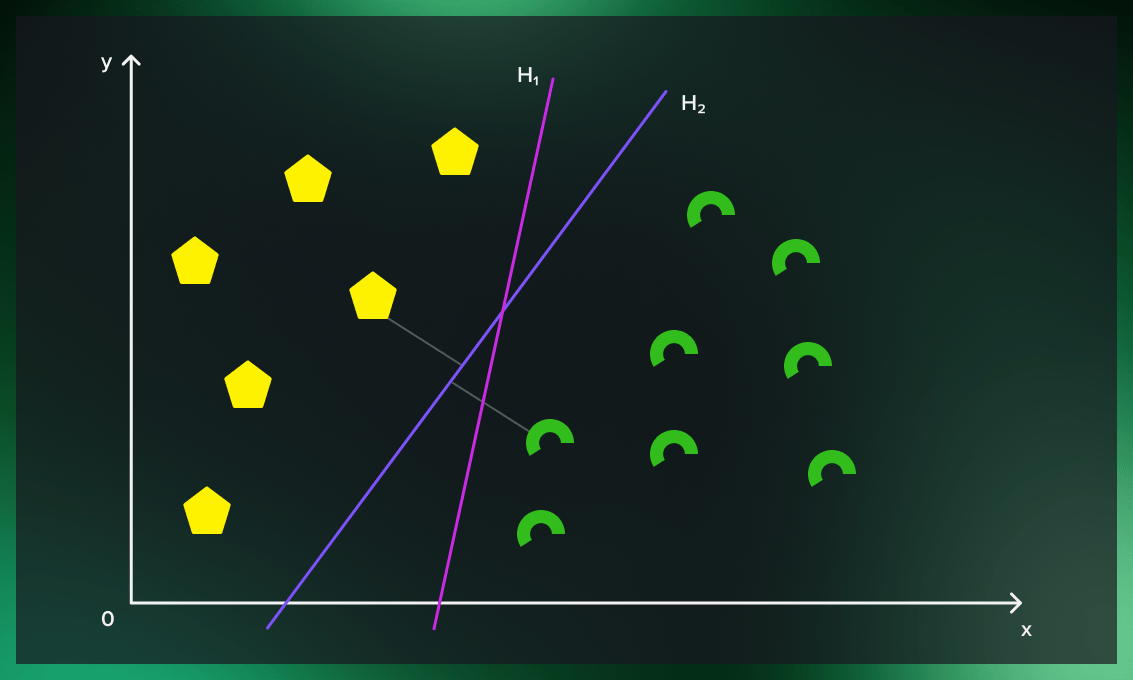
Support Vector Machines (SVM) are powerful supervised learning models used for classification and regression tasks. They excel in scenarios where clear boundaries between classes exist within data. SVM works by finding the hyperplane that best separates different classes in a high-dimensional feature space, maximizing the margin between classes to enhance generalization. This method is effective in handling complex datasets and is robust against overfitting, making SVM a popular choice in various fields such as image recognition, bioinformatics, and text classification. Despite its strengths, SVM's performance heavily relies on appropriate kernel selection and parameter tuning, which can be challenging in large-scale datasets or when classes are overlapping.
This algorithm was selected based on its notably inferior performance in the comparison. While versatile and applicable across various contexts, its efficacy is notably limited in this specific scenario.
Some advantages
Support Vector Machines (SVM) excel in creating robust decision boundaries for complex datasets with high dimensions. Yet, their reliance on kernel selection and parameter tuning can hinder performance. SVMs also demand considerable computational resources, making them less ideal for large-scale datasets. Additionally, they may struggle with noisy or overlapping data, posing challenges in real-world applications. Thus, while SVMs offer powerful tools for classification, their effectiveness depends heavily on meticulous parameter optimization and data characteristics.