K-Nearest Neighbors
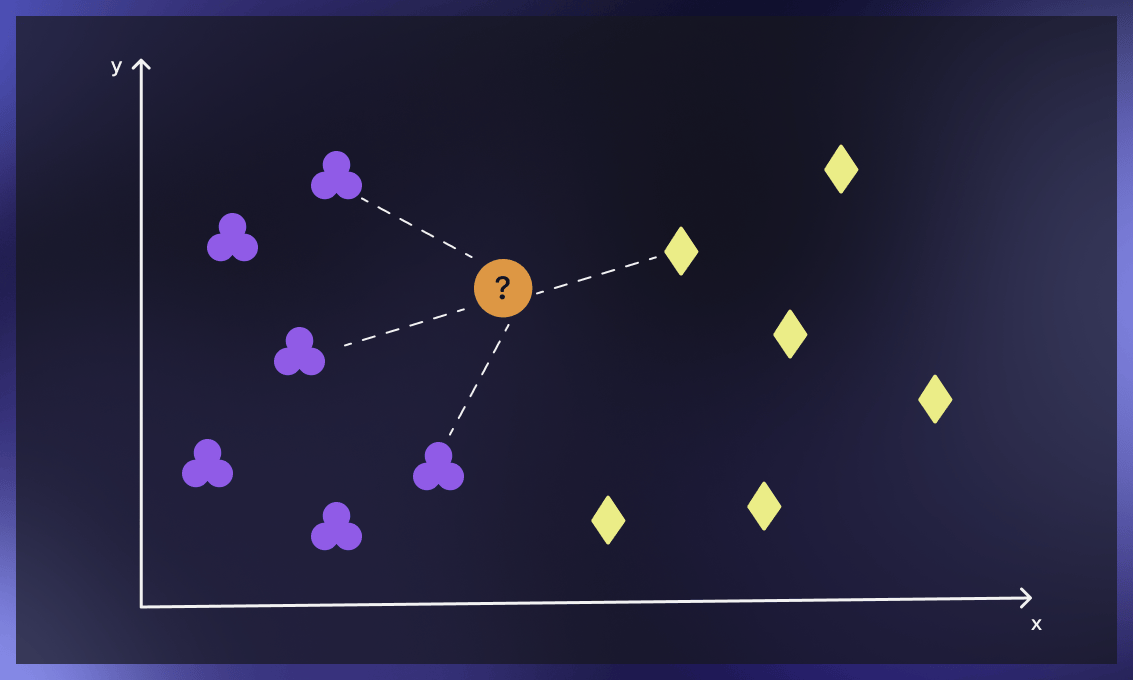
The K-Nearest Neighbors (KNN) algorithm classifies new data based on similarity to previously labeled data. It calculates the distance between a new data point and all training points, selecting the K nearest neighbors. Classification is done by majority vote (for classification) or averaging (for regression). Choosing the optimal K value is crucial for performance.
Many advantages
One of the key advantages of KNN is its non-parametric nature, which means it does not assume any underlying distribution for the data. This versatility allows it to perform effectively in real-world scenarios where data distributions are often unknown or complex. KNN also accommodates various distance metrics, such as Euclidean, Manhattan, or Minkowski distances, enabling customization based on specific problem requirements or dataset traits. Furthermore, KNN is robust to noise, particularly when the value of 𝑘 k is chosen appropriately. The algorithm's reliance on majority voting among neighbors helps mitigate the impact of outliers or noisy data points.
Limitations
Selecting an optimal 𝑘 k value is crucial but can be challenging, impacting the algorithm's performance significantly. KNN is sensitive to irrelevant features and struggles with high-dimensional data, where distances may lose meaning.
"KNN is like a digital Sherlock Holmes, solving mysteries based on the company it keeps."
Peter Harrington, from his book "Machine Learning in Action."