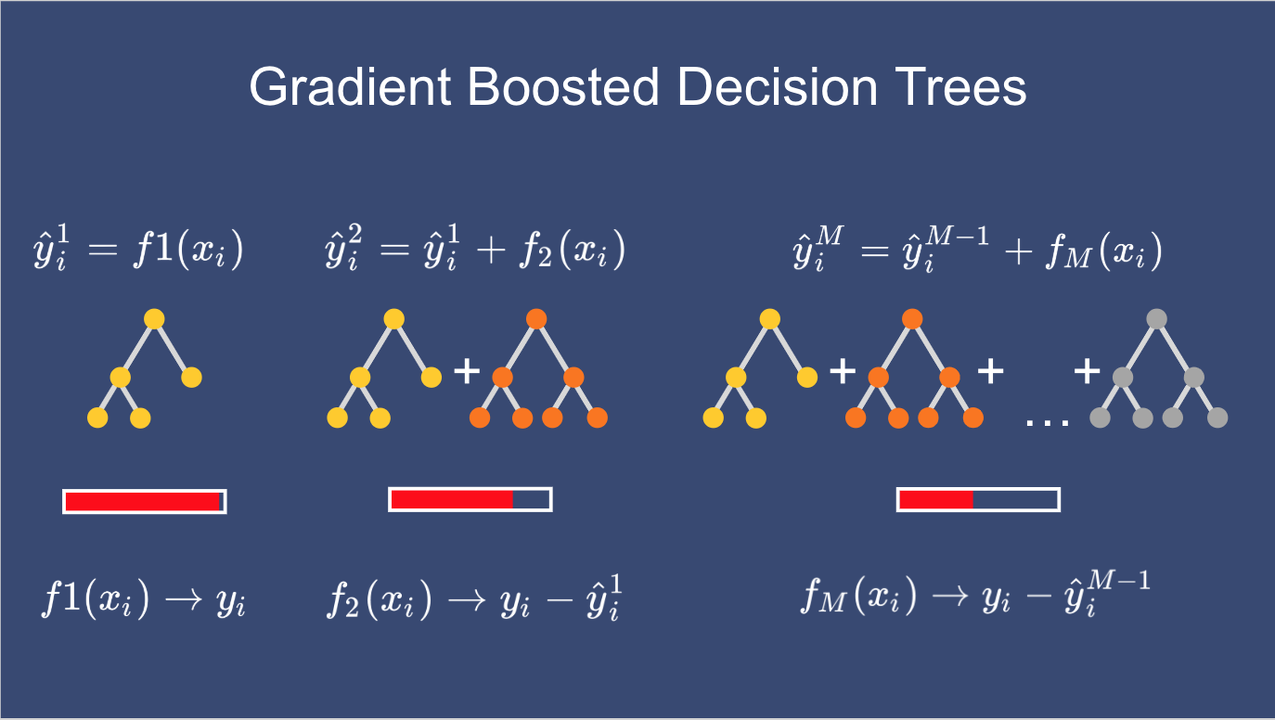
Gradient Boosting
Gradient Boosting is a powerful machine learning technique used for both regression and classification tasks. It builds an ensemble of weak learners, typically decision trees, in a sequential manner, where each subsequent model corrects the errors of its predecessor. This iterative approach allows Gradient Boosting to achieve high accuracy by minimizing the loss function, making it particularly effective in handling complex datasets and uncovering intricate patterns. Despite its computational intensity and sensitivity to hyperparameters, Gradient Boosting's ability to produce robust models has made it a favorite among data scientists and machine learning practitioners.
Many advantages
The advantages of Gradient Boosting are numerous. It is highly flexible and can be used for both regression and classification problems. Its ability to model complex relationships and interactions in the data often leads to superior predictive performance compared to other algorithms. Gradient Boosting also includes built-in feature selection, which helps in identifying the most relevant features automatically. Additionally, it can handle missing data well and is robust to overfitting if the parameters are tuned correctly.
Limitations
It is computationally intensive and can be slow to train, especially with large datasets. The algorithm also requires careful tuning of parameters, which can be complex and time-consuming. Gradient Boosting models can be prone to overfitting if not properly managed. Additionally, the results can be difficult to interpret, making it less transparent compared to simpler models.